DeepSeek深夜更新后自曝:我是V4(?!)
DeepSeek深夜更新后自曝:我是V4(?!)不更是不更,一更就是个大动作,DeepSeek V4可能真的要来了!
来自主题: AI资讯
6635 点击 2026-04-08 17:33
 搜索
搜索
不更是不更,一更就是个大动作,DeepSeek V4可能真的要来了!

就在大家都急头白脸地等待DeepSeek-V4的时候,冷不丁一篇新论文引起了网友们的注意—— 提出新稀疏注意力机制HISA(分层索引稀疏注意力),突破64K上下文的索引瓶颈,相比DeepSeek正在用的DSA(DeepSeek Sparse Attention)提速2-4倍。

ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。
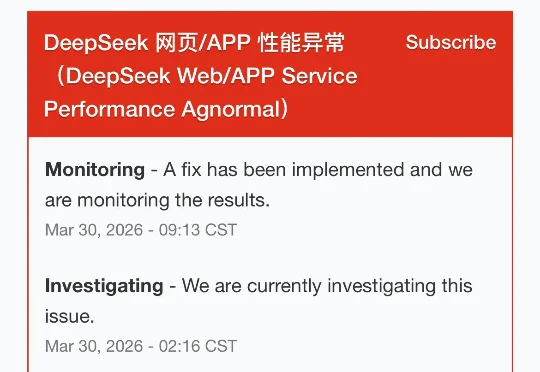
从3月29日晚21时左右起,国内大模型产品DeepSeek的网页端与APP端服务器持续处于崩溃状态,大量用户反馈无法正常访问对话服务。
看过 HBO 神剧《硅谷》(Silicon Valley)的朋友,想必都对那个名为 Pied Piper(魔笛手)的虚构公司念念不忘。

今日凌晨,小米MiMo大模型系列重磅三连更:旗舰基座大模型MiMo-V2-Pro、全模态Agent模型MiMo-V2-Omni、MiMo-V2-TTS,其最新发布的这三大模型都是为优化智能体能力打造。

3月17日,楽天(乐天)集团正式发布了Rakuten AI 3.0模型,号称是“日本国内最大规模的高性能AI模型”。官方宣传的参数量为约7000亿,并且日语特化,Apache 2.0开源许可,还拿了日本经产省和NEDO的GENIAC项目补助。

我们独家获悉,外界千呼万唤的DeepSeek-V4将于4月正式上线。作为梁文锋打磨已久的多模态大模型,DeepSeek-V4除了在Coding能力上跃升之外,还将在LTM(long term memory长期记忆)上取得突破。
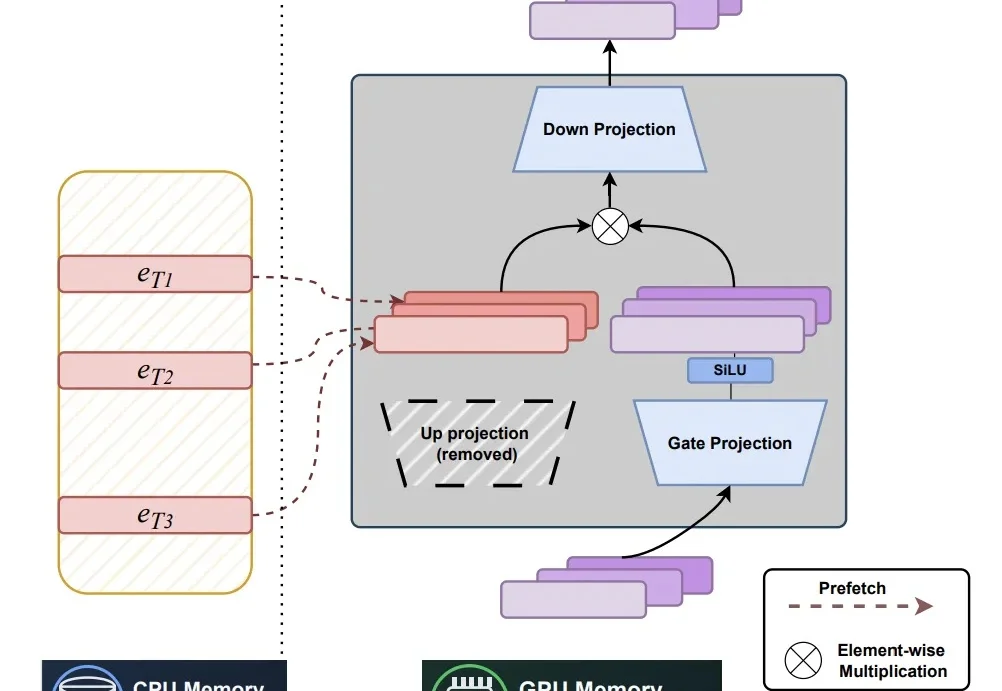
近年来,随着大语言模型规模与知识密度不断提升,研究者开始重新思考一个更本质的问题:模型中的参数应如何被组织,才能更高效地充当「记忆」。

OpenAI的最新研究揭示了一个反直觉的真相:越强大的推理模型,越管不住自己的「脑子」。在CoT-Control套件测试的13款前沿模型中,DeepSeek R1控制自身思维链的成功率仅为0.1%,Claude Sonnet 4.5也只有2.7%。